1 Introduction
Autoencoders learn low-dimensional representation of the data in unsupervised way by aiming to imitate the identity function i.e. reconstruct the original data while having a low-dimensional representation bottleneck in the process. In other words, Autoencoders are neural networks trained to generate output y that is as close to the input x, and an internal layer that gives the representation z(x) for each new input.
Composed of two networks:
- Encoder : Maps high-dimensional input to low-dimensional latent representation, usually .
- Decoder : Outputs data as close to original from latent representation.
Encoder network is generally used to accomplish dimensionality reduction when and can be seen as a non-linear generalization to PCA.
Deterministic AE
- Denoising AE
- Sparse AE
- Contractive AE
Consider random variables x and z, with g being deterministic decoder (generator) and f being deterministic encoder. The process looks like:
Our goal is to generate or in other words sample from distribution . If we know the distribution to latent variable z, then expressing x is just taking marginal likelihood over latent variables with the conditional distribution of , or if we have access to ground truth latent encoder, we can also write
Using log likelihood objective , we can optimize by minimizing the NLL.
But generally, z is not known, and primary goal of a generative model is to create output from scratch. So, we need a distribution so that z can be sampled from the distribution. You might ask, why can’t an AE be used for this, where we can use the encoder to get the sample z? Firstly, encoder works on an input, and secondly, is optimized to work as a identity lookup table. The latent space might not be structured, and AE doesn’t provide any guarantee about the structure of the latent variable distribution.
2 Likelihood
To calculate the intractable data likelihood , we make following assumptions:
- Hypothesis space is modelled using a product mixture of distributions (e.g., Gaussians or Bernoullis) with a prior (usually Gaussian). Thus, VAEs can be seen as an infinite mixture of Gaussians. To prevent learning infinite set of parameters over discrete latent space, VAE uses a function that outputs the parameters of a continuous latent variable, and smoothens the latent space.
- Importance sampling using another density . Instead of approximating the integral over all z (because most of the term will be near zero), we want to sample z from the distribution whose sample places maximum likelihood on x . Optimal .
- Use variational inference to estimate p by modeling parametrized by . Posterior distribution uses approximation function that outputs the parameters of the distribution and can be seen as probabilistic encoder.
Our goal will be to use the representation of the distribution to derive a term called the Evidence Lower Bound (ELBO), which gives a lower bound on the evidence. Evidence is written as log likelihood of the observed data: . ELBO gives a proxy objective that can be optimized with respect to a latent variable model, and in the best case (when true distribution is learned), ELBO exactly equals the evidence.
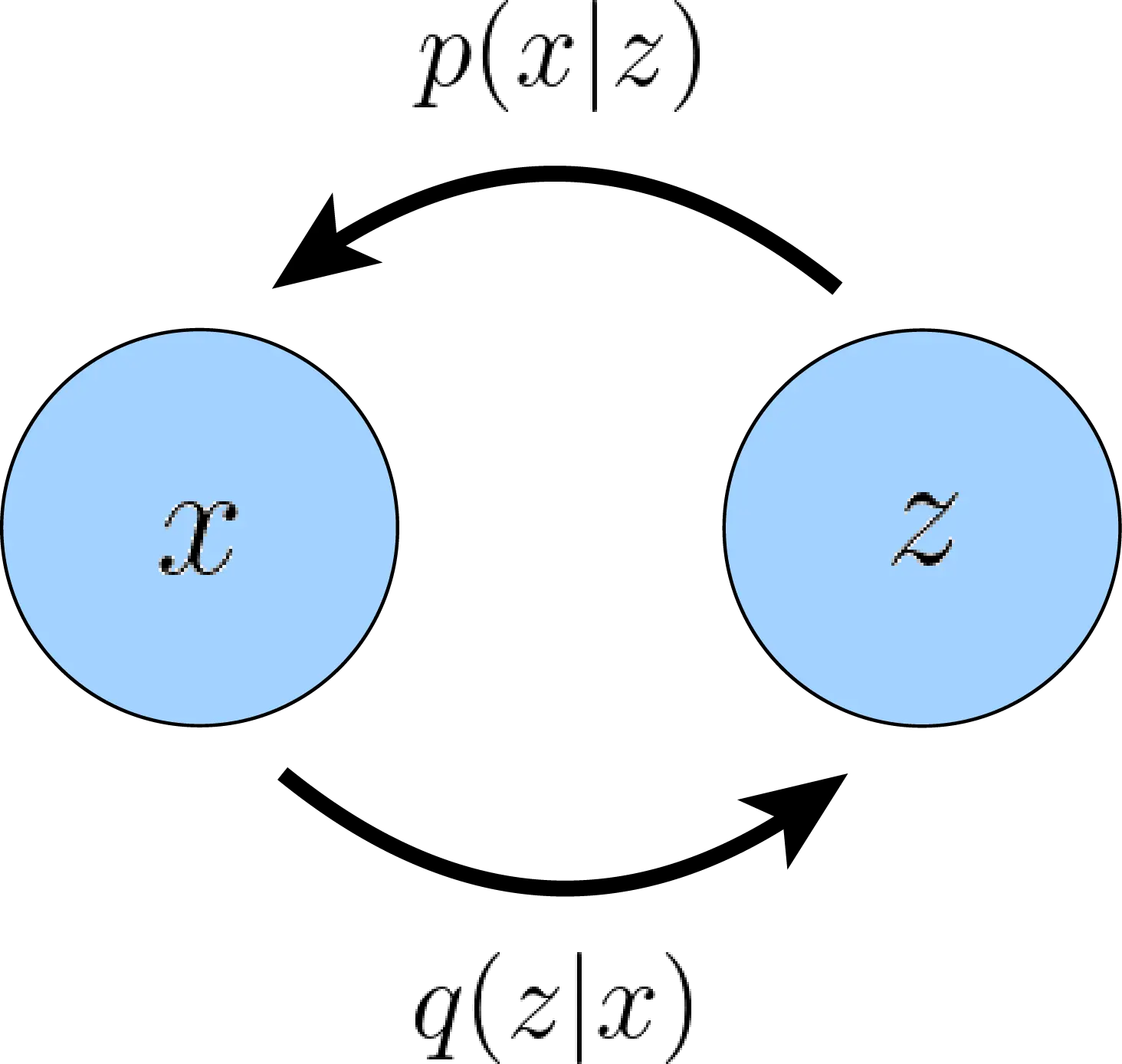
3 Objective
The estimated posterior needs to be close to best approximation , and is measured using reversed KL divergence .
Why use reverse KL?
Doesn’t KL measure how many bits is required to estimate p using q? Then, why are measuring how many bits are required to go from p to q, when instead we are approximating p with q?
We can rearrange the terms to get the learning objective. To get optimal parameters , we want to minimize the KL divergence between the two distributions and maximize the log likelihood of generating real data .
This term is known as Variational lower bound or Evidence lower bound (ELBO). For more details on why variational bound, refer to this amazing post. Let’s understand what each term in the objective represents:
- Reconstruction term: Measures how well are we able to convert a latent vector into an observation .
- Prior matching term: Measures how well is the learned encoder matching our prior belief over latent variables, .
Lower bound is achieved because KL-divergence is always non-negative, thus .
As briefed in the assumptions, encoder of the VAE is generally chosen to be multivariate gaussian with diagonal covariance, and the prior is selected to be a distribution, we can easily sample from like standard multivariate Gaussian.
While training the model, the backward pass follows:
- Computing the KL term using closed form solution.
- For computing the likelihood term:
- Encode x using
- Sample z from the distribution
- Decode z to obtain parameters for likelihood distribution
- Measure the reconstruction error by computing the probability distribution
We want to compute gradient of with respect to parameter , but gradient does not follow z as it random due to being sampled from the distribution. The trick is to fix the parameters and write z as deterministic variable where .
After training the VAE, to use it as a generative model, we can simply sample a latent variable from the latent space, and run it through the decoder. VAE are able to learn a compressed, low-dimensional representation of the high-dimensional data manifold as dimension of is much less than , and the output can be controlled by carefully editing the latent variable.
4 Hierarchical VAE
Introduced in [2, 3], HVAE can be seen as a generalization of VAE to multiple hierarchies of latent variables. We can generate arbitrary graphical models to condition latent on all other previous latents, which themselves are generated from other higher-level, more abstract latents.
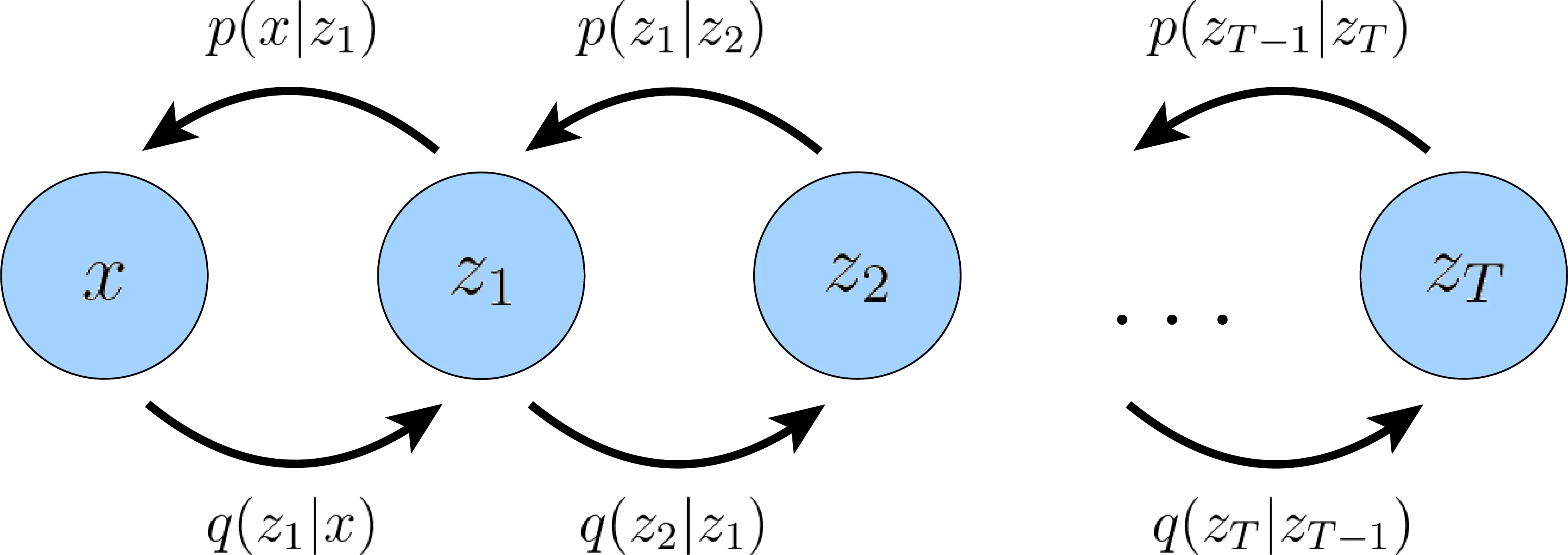
To consider a simple example, take a Markovian chain of VAEs, where each decoding latent variable is dependent on the previous one . This can be simply seen as a recursive stack of VAEs and we can model the joint distribution, and the posterior as:
And similarly, ELBO can be extended:
5 References
- 33 Generative Modeling Meets Representation Learning – Foundations of Computer Vision
- Understanding Diffusion Models: A Unified Perspective
- From Autoencoder to Beta-VAE | Lil’Log
- Eric Jang: A Beginner’s Guide to Variational Methods: Mean-Field Approximation
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Sønderby, C. K., Raiko, T., Maaløe, L., Sønderby, S. K., & Winther, O. (2016). Ladder variational autoencoders. Advances in neural information processing systems, 29.
- Kingma, D. P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., & Welling, M. (2016). Improved variational inference with inverse autoregressive flow. Advances in neural information processing systems, 29.