what's the limitation of CNNs?
No global state due to local patches.
Tokens
- vector of neurons encapsulating bundle of information. Any type of multimodal input (natural language, audio, image, video) can be tokenised into d-dimensional vectors.
- Concatenated together to form a matrix where N is the number of tokens and D is dimension of each token or channels, with each row denoting the encoding for input sequence.
Transformer architecture
A single transformer layer comprises two stages: Attention mechanism that mixes the context from features in different token vectors, and second stage that transforms the features within each token vector. After converting each input sequence into token embeddings, transformers determine the similarity, correlation, alignment between each token using alignment scores which is then converted into probability distribution using a softmax function known as attention weights. Using attention weights, some part of information is highlighted and model can make predictions by focusing or ignoring information.
- Linear combination of neurons or Linear layer: or , where A is the attention coefficient matrix of size NxN.
- Linear combination in transformers is a low rank operation as each element in a token is getting multiplied by same weights.
- To distribute attention between different input tokens, following constraints are added: .
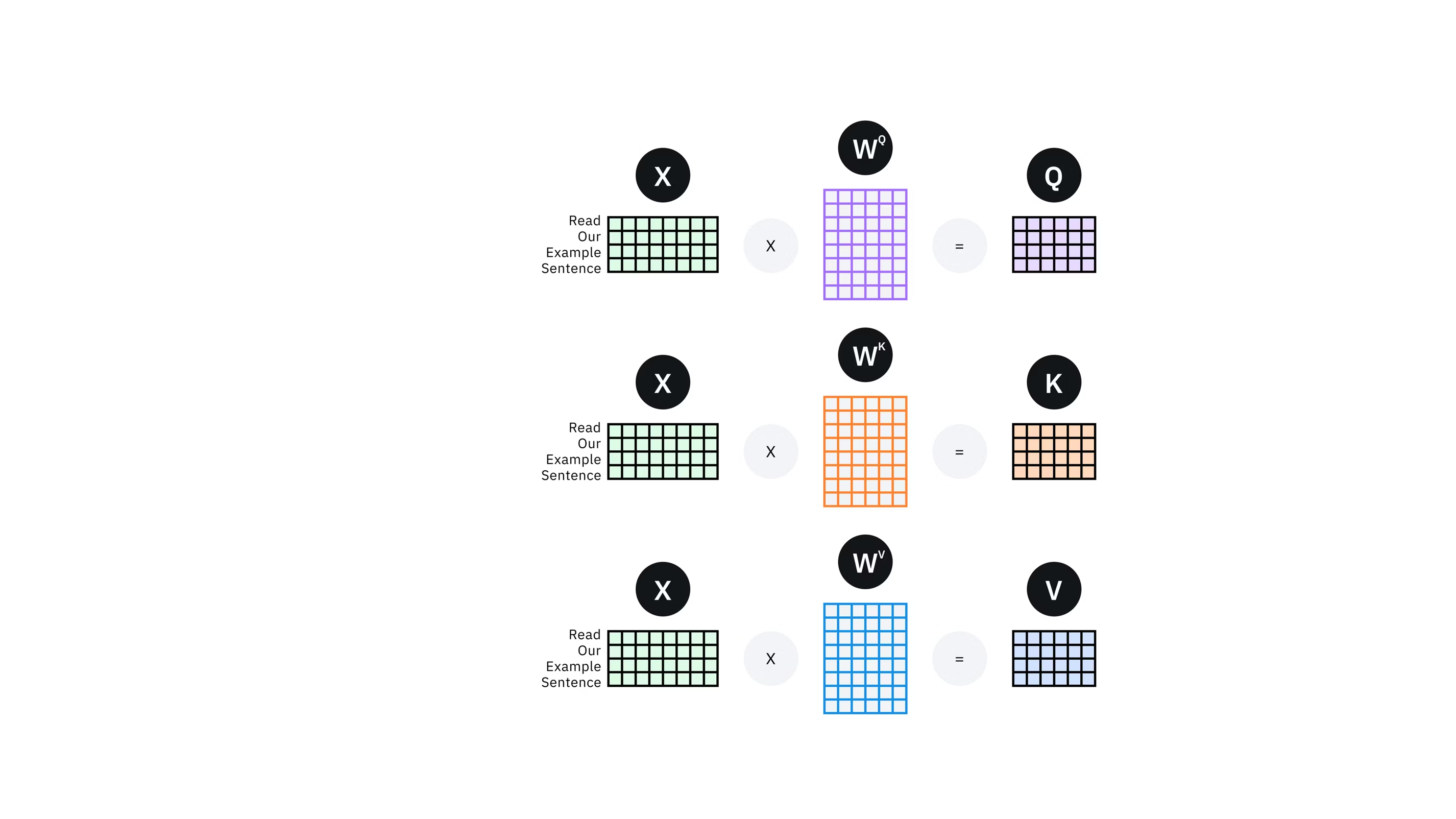
Self-attention: Determining the attention weights is done by using the same input token to calculate the queries, keys and values vector.
- Query : Input token is converted into information intent inducing vector where is the learned parameter of size . Informally, Query represents “what information a token is seeking”.
- Key : Each token contains implicit information represented using key where is the learned parameter of size . Informally, key vector of an input token defines what information does the token hold.
- Value : Extracts the relevant information from input tokens where is the learned parameter of size .
For a single query :
- Compute alignment score using dot-product:
- Normalise with a probability distribution:
- Output attention:
In matrix form: , where and .
Q and K are learned in the same vector space, which is used by the dot product to compute the similarity score, and V vector is learned in a potentially different space. Computing the attention then means that values are projected in Q-K space weighted by the similarity scores.
flowchart TD subgraph Input X --> Wq X --> Wₖ X --> Wᵥ end Wq --Q--> mm1["matmul"] Wₖ --K--> mm1 Wᵥ --V--> mm2["matmul"] mm1 --> scale scale --> softmax softmax --> mm2 mm2 --> Y
Reason for normalizing with
Assume are i.i.d. with , then and . So, as dimension increase, dot products can be large in magnitude that saturates softmax and gradients becomes exponentially small. We want .
History
Attention was first introduced by Bahdanau et al. (2014) which used additive attention which used vectors of different tokens (and not the input token as done in self-attention) as key vectors. Luong et al. (2015) introduced multiplicative or dot-product to calculate the alignment scores.
Vaswani et al. (2017) introduced Transformer architecture that removed <>, self-attention mechanism, normalized alignment score and positional encoding of the input tokens.
Multi-head Attention: What we described so far can be termed as an Attention head. We can use multiple attention heads to learn multiple patterns. Formally, suppose we have H heads, then and , where each have same dimension, and .
All attention head outputs are still linear combinations and a function of input. Softmax induces non-linearity, but output space is still a subspace of the space spanned by inputs. To introduce non-linearity, transformer architecture uses standard feed-forward NN or MLPs.
Non-Linearity: , where can be an MLP.
Transformer architecture also uses residual or skip connections and LayerNorms to improve training efficiency.
Add more on the reason for LayerNorms and skip connections later.
Computational complexity
- Attention
- Compute :
- Evaluating dot-product:
- softmax:
- Multiply with V:
- Feedforward network: D-dimensional inputs and D-dimensional outputs for N inputs:
- Depending on the task, either of attention layer or feedforward layer can be computationally expensive. Generally, attention layer is more expensive due to quadratic proportional dependence to length of input token sequence.
Now, we can stack multiple layers on top of each other to create a deep Transformer neural network.
Think about the similarities between GNN and Transformers. Why is a transformer is similar to a fully connected GNN?
Todo
- Efficient Transformers
Positional Encoding and Embeddings
Positional encoding: Convince yourself that vanilla transformer architecture is equivariant to input permutations, i.e. permuting the input permutes the output. This can be mitigated by assigning a unique position to each input token in the input itself. Modifying the input vectors by adding the position vectors onto the token vectors give , where p is the positional encoding of the input token in the data.
Why does adding a new vector to the input vector not corrupt the information?
Because randomly sampled two vectors in a high dimensional space tend to be nearly orthogonal implying that model can process token information and token position separately even when they’re added in a single entity.
Approach proposed in Vaswani et al. (2017) is based on Fourier basis where for a given position n the associated position encoding vector is:
One nice property of sinusoidal representation is that relative positions is a linear function of and can be encoded using a rotation matrix. To see this (referenced from 2Aakash Kumar Nain - Rotary Position Encoding ), let’s take a two dimensional position vector, :
Using trigonometric identities, and , we can write:
Thus, we can write as linear function of with a rotation matrix:
Problems with sinusoidal position encodings:
- Relative positions are easier to encode but harder to learn due to direction of the sinusoidal representations being jagged. This indicates that model might have to devote a large time of its finite training schedule to attend to learning relative positions.
- Additive: TODO
How do you handle a continuous input like image or audio or video for transformers? Think about tokenisation, embedding and positional encoding.
- Image: Divide the input image into patches. taking an example of greyscale image of 100x100 size. then it can be flattened into 10,000 sized vector. Tokenisation and embedding is done in one go, and positional encoding can be applied same as transformer paper (sinusoidal) or maybe RoPE.
- For images: we can create patches of say 5x5 like a CNN and then use the attention layers to learn about spatial relationships rather than just flattening the vector. Patches can be concatenated in a batch to allow for flexible learning.
- Audio: divide the the audio signal into discrete patches at fixed length (say 0.1ms) and record the signal at that position. Concatenating the sequence as a vector, and we have the input embedding.
- For audio: if you take fixed windows (like 0.1 ms), what structure are you assuming about the signal? Do raw waveform chunks behave like good tokens, or would something like time-frequency representations (e.g., spectrograms) give better inductive bias?
- How to detect if there is a need for separate embedding function or if we can use the pixel values or waveform amplitude as embeddings directly?
- You mentioned positional encoding—good—but ask yourself: for images and audio, is 1D positional encoding sufficient, or do you need something that captures 2D (images) or continuous time structure (audio) more explicitly?
Why is transformer sinusoidal positional encoding using alternating sines and cosines? And why is RoPE applying the same rotation matrix to the query vector?
- 2D encodings for images
To-Read
- Jane Street Blog - Using group theory to explore the space of positional encodings for attention
- [2511.05963] Next-Latent Prediction Transformers Learn Compact World Models
- [2604.12946] Parcae: Scaling Laws For Stable Looped Language Models
- [2606.18206] Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
- The Annotated Kolmogorov-Arnold Network (KAN) | Alex L. Zhang