1 Score Based Generative Models
We have shown in VDM that approximating the score function is analogous to predicting the posterior mean or noise . We can now look at another class of models: Score-based Generative models that directly learn the score function and then sample from the distribution using MCMC methods like Annealed Langevin sampling.
Recall, in EBMs, we represent an arbitrary distribution using Boltzmann energy function, , where is arbitrary, flexible and parametrizable function and is the normalizing or partition function written as . One way to learn such a distribution is Maximum likelihood estimation but requires tackling the constant which can be computed using MC estimate of the samples, but that might be difficult to get for complex functions.
To make likelihood training feasible, models restrict their architectures or approximate normalizing constant:
- Causal convolutions in AR models: likelihood is written using chain rule that avoids normalizing constant
- Normalizing flows: uses change-of-variables to solve the problem differently.
- VAE: Avoid latent variable integral using ELBO maximization.
- MCMC sampling: approximate expectation using real samples or the current best samples.
Learning the score function using neural network approximation is one way to avoid modeling the normalization constant.
We can then compute the score either by directly modeling the unnormalized energy function or approximating the score function with a neural network . The neural network is then trained using the fisher divergence measure between estimated score and ground truth score function.
Why use fisher divergence and not other divergence measures?
Due to the flexibility of fisher divergence, doesn’t need to be any normalized distribution, and simply compares the distance between ground truth score and the learned model.
What does score function mean, what does it represent?
Score function is the gradient of the log likelihood of the data . Geometrically, it defines a vector field over the space of pointing towards the peaks.
add a plot for langevin dynamics and score function.
After learning the true distribution by modelling the score function, we can just sample from the distribution. Langevin sampling is an MCMC sampling procedure that enables drawing sample from the distribution using just the score function which we’ve learned as , and arbitrary isotropic Gaussian noise. We update the values and iteratively follow the direction until a mode is reached.
and . As and , the sequence converges to the mode of the distribution. The extra noise term ensures that the procedure is not entirely deterministic and sufficient exploration is performed at each iteration.
For what scenarios, we can have access to the ground truth score function, and for what, do we not have?
In case, we do not have access, we can use score matching techniques to minimize fisher divergence. Combination of learning the score function using score matching, and sampling using Langevin dynamics is known as SCGM.
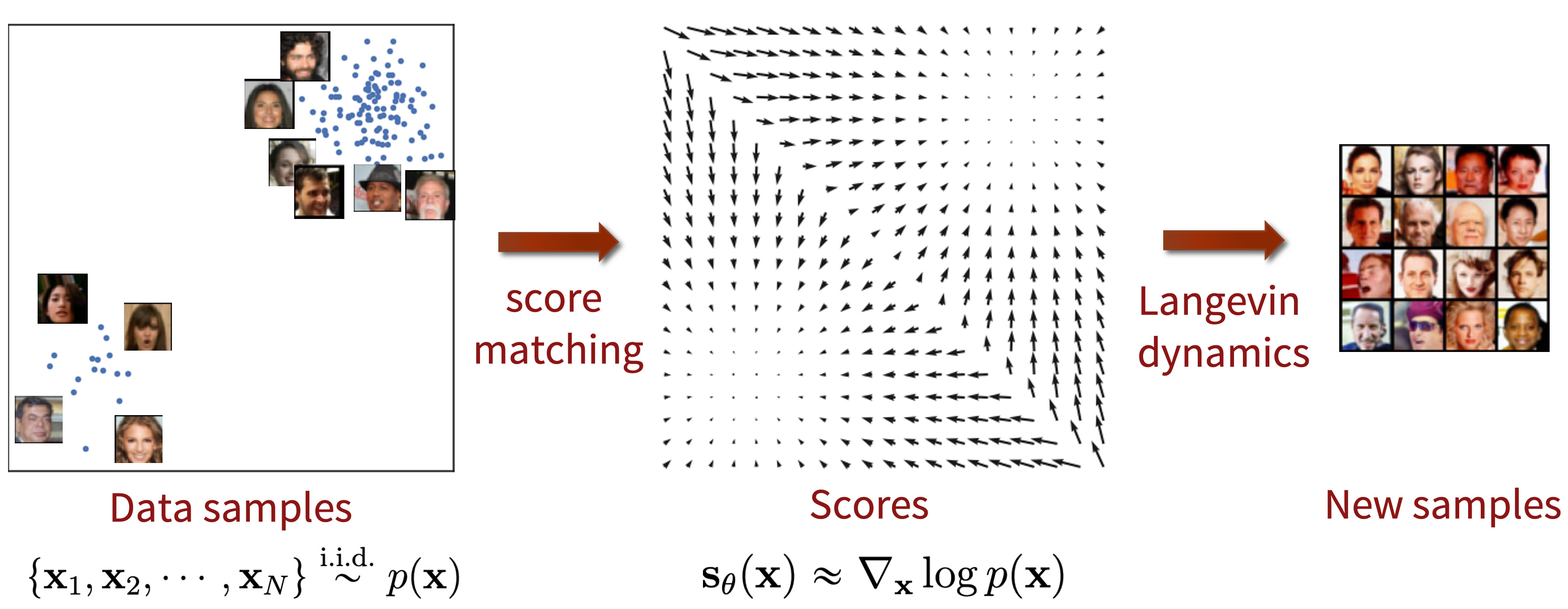
What are the three main problems of vanilla score matching?
- From manifold hypothesis, we know that x lies on a low-dimensional manifold in a high-dimensional space. Computing log of the probability of the points not in low-dimensional manifold is undefined, which means, even if we have access to ground truth score function, it leads to numerical instability errors when learning on low-probability points.
- Model is trying to estimate the expectation of L2 norm of difference between learned score function and ground truth. In low-density regions, where few data points are available, probability assigned to the point will be very low, and model will not gain any significant information from the input. Sampling from Langevin dynamics involves starting from a random point and iteratively following the score. Starting sample is highly likely to be in low-density regions. Due to inaccurate scores in those regions, model may never find the mode, and the final generated sample may be suboptimal.
- Langevin sampling may not consider the weight of the mixture of distributions. Suppose the distribution is p(x)=cp1(x)+c2p2(x). Computing the score using gradient of log probability erases the weight of the distribution. The learned score function may then be agnostic to the different weights, and Langevin sampling then leads to a different peak irrespective of the strengths in the combined distribution.
How to mitigate this problem? How can the problem be summed in one sentence? The problem is due to lack of signal in low-density regions. This is equivalent of using an unseen image from the true distribution to the network.
The solution is quite simple, yet elegant, and follows the same process as VDM, i.e. to perturb data points with noise, and train a score based model on the noisy data. This fixes two of the three previously stated problems. Suppose, we perturb a high-dimensional distribution with additional Gaussian noise: .
- Due to the support of Gaussian being the entire space, a perturbed sample is no longer confined to high-density region, . Mathematically, this is equivalent of taking a convolution with a Gaussian kernel:
- Adding Large Gaussian noise smoothens out the peaks of the distribution more aggressively, and model can get training signal from low-density areas.
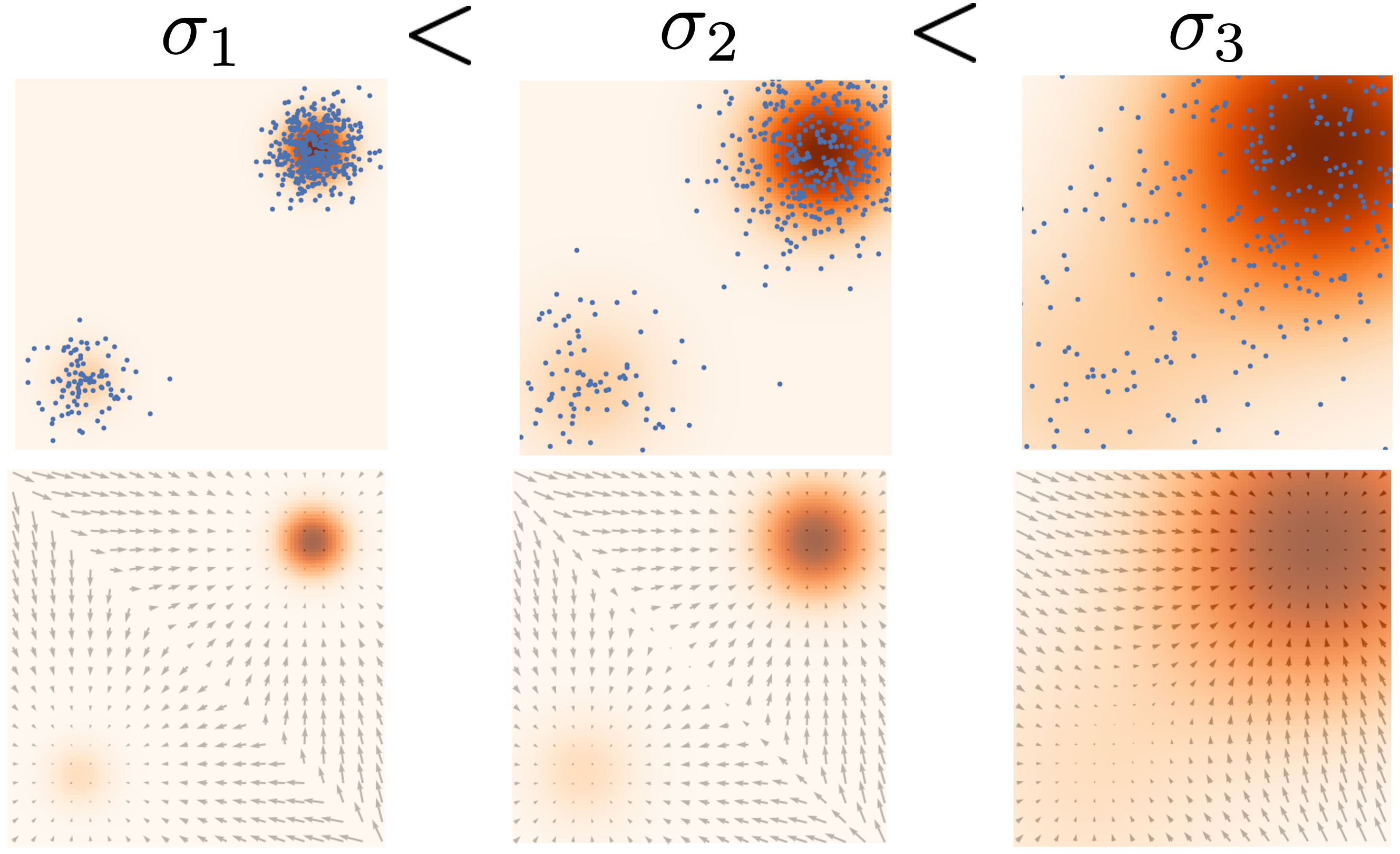
To fix the third problem is a little tricky, because adding single big noise could alter the distribution and the model could potentially be learning an incorrect distribution altogether. The solution to this is actually, quite similar to VDMs again, i.e. add multiple noise at successive levels that result in intermediate distributions. Distributions with smaller noise respect the weighing coefficients in a mixture of distributions while larger noise the model can learn global structure to sufficiently guide the score matching objective.
Suppose, we always perturb the data with isotropic Gaussians.
- Take L Gaussians with increasing standard deviations: .
- Perturb the data distribution with each of the noisy Gaussian to obtain a sequence of more noisy distributions:
- Drawing samples from each of the distribution is trivial, , and computing
- Train a neural network approximator to learn the score function for all noise level simultaneously. The objective is a weighted sum of fisher divergences of each noisy distribution
After training, produce samples by running Annealed Langevin dynamics which is just Langevin dynamics that runs for each distribution in sequence, and initialization for each sampling is the output of the previous sampler. You can note how the noise reduces with each new sampler, and the most recent sample is used as the initializer to carry-forward the information learned from previous step. This can be interpreted as reverse diffusion process of a VDM, where an isotropic noisy vector is gradually refined towards lesser noise levels.
Score matching techniques
- Explicit score matching
- Implicit score matching
- Denoising score matching
- sliced score matching
2 References
- Song, Yang, and Stefano Ermon. “Generative modeling by estimating gradients of the data distribution.” Advances in neural information processing systems 32 (2019).
3 Score Based Generative Modelling Using SDEs
Write a table that compares between diffusion and SDE formulation of diffusion and compares forward and reverse process with an SDE.
Time reversal of diffusion/reverse SDE
- Why do we want to reverse an SDE? What do we aim to get by tracing back the forward trajectory of an SDE?
- We can’t trace back the trajectory exactly, and get back the initial position, but what we can do aim is, at initial time , the particles should have the position as per the forward SDE’s initial distribution.
- Or even stronger assumption, at any point t, the position of the particles match the distribution of the forward trajectory.
- We say that distribution is matched when the probability mass is conserved as the process progresses.
- Andersen’s theorem provides the solution to reverse an SDE and is mathematically stated as , where .
Take an ODE, reverse it using sign change
- sampling methods for ODE
- first-order method: Euler’s method
- second-order method: Runge-Kutta
For an SDE,
- sample using Euler-Maruyama method
- reverse using Andersen’s theorem
- Ornstein-Uhlenbeck: linear drift + constant diffusion.
We can take the DDPM process and write it in the form of continuous time SDE. To see the process, let’s start with forward diffusion: , where . Any iterative process can bee converted into an ODE. For an SDE conversion, we’ll follow similar approach.
For N-step diffusion process:
- Define a step size
- Consider auxiliary noise level where . We define this way because as .
- Similarly define and
- Following the diffusion process,
As ,
Reverse sampling equation of DDPM can be written as SDE as
Following similar iterative update scheme, this can be converted into DDPM reverse sampling equation: .
Why DDPM SDE is called Variance-Preserving SDE?
Why SMLD SDE is called Variance exploding SDE?